Рассмотрим Биномиальное распределение, вычислим его математическое ожидание, дисперсию, моду. С помощью функции MS EXCEL БИНОМ.РАСП() построим графики функции распределения и плотности вероятности. Произведем оценку параметра распределения p, математического ожидания распределения и стандартного отклонения. Также рассмотрим распределение Бернулли.
Определение . Пусть проводятся n испытаний, в каждом из которых может произойти только 2 события: событие «успех» с вероятностью p или событие «неудача» с вероятностью q =1-p (так называемая Схема Бернулли, Bernoulli trials ).
Вероятность получения ровно x успехов в этих n испытаниях равна:
Количество успехов в выборке x является случайной величиной, которая имеет Биномиальное распределение (англ. Binomial distribution ) p и n – являются параметрами этого распределения.
Напомним, что для применения схемы Бернулли и соответственно Биномиального распределения, должны быть выполнены следующие условия:
- каждое испытание должно иметь ровно два исхода, условно называемых «успехом» и «неудачей».
- результат каждого испытания не должен зависеть от результатов предыдущих испытаний (независимость испытаний).
- вероятность успеха p должна быть постоянной для всех испытаний.
Биномиальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для имеется функция БИНОМ.РАСП() , английское название - BINOM.DIST(), которая позволяет вычислить вероятность того, что в выборке будет ровно х «успехов» (т.е. функцию плотности вероятности p(x), см. формулу выше), и интегральную функцию распределения (вероятность того, что в выборке будет x или меньше «успехов», включая 0).
До MS EXCEL 2010 в EXCEL была функция БИНОМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности p(x). БИНОМРАСП() оставлена в MS EXCEL 2010 для совместимости.
В файле примера приведены графики плотности распределения вероятности и .

Биномиальное распределения имеет обозначение B ( n ; p ) .
Примечание : Для построения интегральной функции распределения идеально подходит диаграмма типа График , для плотности распределения – Гистограмма с группировкой . Подробнее о построении диаграмм читайте статью Основные типы диаграмм.
Примечание : Для удобства написания формул в файле примера созданы Имена для параметров Биномиального распределения : n и p.

В файле примера приведены различные расчеты вероятности с помощью функций MS EXCEL:

Как видно на картинке выше, предполагается, что:
- В бесконечной совокупности, из которой делается выборка, содержится 10% (или 0,1) годных элементов (параметр p , третий аргумент функции = БИНОМ.РАСП() )
- Чтобы вычислить вероятность, того что в выборке из 10 элементов (параметр n , второй аргумент функции) будет ровно 5 годных элементов (первый аргумент), нужно записать формулу: =БИНОМ.РАСП(5; 10; 0,1; ЛОЖЬ)
- Последний, четвертый элемент, установлен =ЛОЖЬ, т.е. возвращается значение функции плотности распределения .
Если значение четвертого аргумента =ИСТИНА, то функция БИНОМ.РАСП() возвращает значение интегральной функции распределения или просто Функцию распределения . В этом случае можно рассчитать вероятность того, что в выборке количество годных элементов будет из определенного диапазона, например, 2 или меньше (включая 0).
Для этого нужно записать формулу: = БИНОМ.РАСП(2; 10; 0,1; ИСТИНА)
Примечание : При нецелом значении х, . Например, следующие формулы вернут одно и тоже значение: =БИНОМ.РАСП( 2 ; 10; 0,1; ИСТИНА) =БИНОМ.РАСП( 2,9 ; 10; 0,1; ИСТИНА)
Примечание : В файле примера плотность вероятности и функция распределения также вычислены с использованием определения и функции ЧИСЛКОМБ() .
Показатели распределения
В файле примера на листе Пример имеются формулы для расчета некоторых показателей распределения:
- =n*p;
- (квадрата стандартного отклонения) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*КОРЕНЬ(n*p*(1-p)).
Выведем формулу математического ожидания Биномиального распределения , используя Схему Бернулли .
По определению случайная величина Х в схеме Бернулли (Bernoulli random variable) имеет функцию распределения :

Это распределение называется распределение Бернулли .
Примечание : распределение Бернулли – частный случай Биномиального распределения с параметром n=1.
Сгенерируем 3 массива по 100 чисел с различными вероятностями успеха: 0,1; 0,5 и 0,9. Для этого в окне Генерация случайных чисел установим следующие параметры для каждой вероятности p:

Примечание : Если установить опцию Случайное рассеивание ( Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию =25 можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца по 100 чисел, на основании которых можно, например, оценить вероятность успеха p по формуле: Число успехов/100 (см. файл примера лист ГенерацияБернулли ).
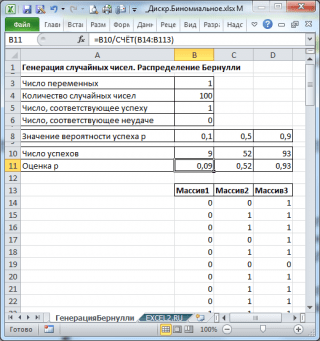
Примечание : Для распределения Бернулли с p=0,5 можно использовать формулу =СЛУЧМЕЖДУ(0;1) , которая соответствует .
Генерация случайных чисел. Биномиальное распределение
Предположим, что в выборке обнаружилось 7 дефектных изделий. Это означает, что «очень вероятна» ситуация, что изменилась доля дефектных изделий p , которая является характеристикой нашего производственного процесса. Хотя такая ситуация «очень вероятна», но существует вероятность (альфа-риск, ошибка 1-го рода, «ложная тревога»), что все же p осталась без изменений, а увеличенное количество дефектных изделий обусловлено случайностью выборки.
Как видно на рисунке ниже, 7 – количество дефектных изделий, которое допустимо для процесса с p=0,21 при том же значении Альфа . Это служит иллюстрацией, что при превышении порогового значения дефектных изделий в выборке, p «скорее всего» увеличилось. Фраза «скорее всего» означает, что существует всего лишь 10% вероятность (100%-90%) того, что отклонение доли дефектных изделий выше порогового вызвано только сучайными причинами.

Таким образом, превышение порогового количества дефектных изделий в выборке, может служить сигналом, что процесс расстроился и стал выпускать б о льший процент бракованных изделий.
Примечание : До MS EXCEL 2010 в EXCEL была функция КРИТБИНОМ() , которая эквивалентна БИНОМ.ОБР() . КРИТБИНОМ() оставлена в MS EXCEL 2010 и выше для совместимости.
Связь Биномиального распределения с другими распределениями
Если параметр n Биномиального распределения стремится к бесконечности, а p стремится к 0, то в этом случае Биномиальное распределение может быть аппроксимировано . Можно сформулировать условия, когда приближение распределением Пуассона работает хорошо:
- p (чем меньше p и больше n , тем приближение точнее);
- p >0,9 (учитывая, что q =1- p , вычисления в этом случае необходимо производить через q (а х нужно заменить на n - x ). Следовательно, чем меньше q и больше n , тем приближение точнее).
При 0,110 Биномиальное распределение можно аппроксимировать .
В свою очередь, Биномиальное распределение может служить хорошим приближением , когда размер совокупности N Гипергеометрического распределения гораздо больше размера выборки n (т.е., N>>n или n/N Подробнее о связи вышеуказанных распределений, можно прочитать в статье . Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье .
Рассмотрим осуществление схемы Бернулли , т.е. прозводится серия повторных независимых испытаний, в каждом из которых данное событие А имеет одну и ту же вероятность , не зависящую от номера испытания. И для каждого испытания имеются только два исхода:
1) событие А - успех;
2) событие - неуспех,
с постоянными вероятностями
Введем в рассмотрение дискретную случайную величину Х - «число появлений события А при п испытаниях» и найдем закон распределения этой случайной величины. Величина Х может принимать значения
Вероятность ![]() того, что случайную величину Х примет значение x k
находится по формуле Бернулли
того, что случайную величину Х примет значение x k
находится по формуле Бернулли
Закон распределения дискретной случайной величины, определяемый формулой Бернулли (1), называется биномиальным законом распределения . Постоянные п и р (q=1-p) , входящие в формулу (1) называются параметрами биномиального распределения.
Название «биномиальное распределение» связано с тем, что правая часть в равенстве (1) это общий член разложения бинома Ньютона ,т.е.
(2)
А так как p+q=1 , то правая часть равенства (2) равна 1
Это означает, что
 (4)
(4)
В равенстве (3) первый член q n
в правой части означает вероятность того, что в п
испытаниях событие А не появится ни разу, второй член ![]() вероятность того, что событие А появится один раз, третий член - вероятность, что событие А появится два раза и наконец, последний член р п
- вероятность того, что событие А появится ровно п
раз.
вероятность того, что событие А появится один раз, третий член - вероятность, что событие А появится два раза и наконец, последний член р п
- вероятность того, что событие А появится ровно п
раз.
Биномиальный закон распределения дискретной случайной величины представляют в виде таблицы:
| Х | 0 | 1 | … | k | … | n |
| Р | q n | … | … | р п |
Основные числовые характеристики биномиального распределения:
1) математическое ожидание ![]() (5)
(5)
2) дисперсия ![]() (6)
(6)
3) среднее квадратическое отклонение ![]() (7)
(7)
4) наивероятнейшее число появление события k 0 - это число которому при заданном п соответствует максимальная биномиальная вероятность
При заданных п и р это число определяется неравенствами
![]() (8)
(8)
если число пр+р не является целым, то k 0 равно целой части этого числа, если же пр+р - целое число, то k 0 имеет два значения
Биномиальный закон распределения вероятностей применяется в теории стрельбы, в теории и практике статистического контроля качества продукции, в теории массового обслуживания, в теории надежности и т.д. Этот закон может применяться во всех случаях, когда имеет место последовательность независимых испытаний.
Пример 1: Проверкой качества установлено, что из каждых 100 приборов не имеют дефекты 90 штук в среднем. Составить биномиальный закон распределения вероятностей числа качественных приборов из приобретенных наугад 4.
Решение: Событие А - появление которого проверяется это - «приобретенный наугад прибор качественный». По условию задачи основные параметры биномиального распределения:
Случайная величина Х - число качественных приборов из взятых 4, значит значения Х -Найдем вероятности значений Х по формуле (1):

Таким образом, закон распределения величины Х - число качественных приборов из взятых 4:
| Х | 0 | 1 | 2 | 3 | 4 |
| Р | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
Для проверки правильности построения распределения проверим чему равна сумма вероятностей
Ответ: Закон распределения
| Х | 0 | 1 | 2 | 3 | 4 |
| Р | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
Пример 2: Применяемый метод лечения приводит к выздоровлению в 95 % случаев. Пятеро больных применяли данный метод. Найти наивероятнейшее число выздоровевших, а так же числовые характеристики случайной величины Х - число выздоровевших из 5 больных применявших данный метод.
Конечно, при вычислении кумулятивной функции распределения следует воспользоваться упомянутой связью биномиального и бета- распределения. Этот способ заведомо лучше непосредственного суммирования, когда n > 10.
В классических учебниках по статистике для получения значений биномиального распределения часто рекомендуют использовать формулы, основанные на предельных теоремах (типа формулы Муавра-Лапласа). Необходимо отметить, что с чисто вычислительной точки зрения ценность этих теорем близка к нулю, особенно сейчас, когда практически на каждом столе стоит мощный компьютер. Основной недостаток приведенных аппроксимаций – их совершенно недостаточная точность при значениях n, характерных для большинства приложений. Не меньшим недостатком является и отсутствие сколько-нибудь четких рекомендаций о применимости той или иной аппроксимации (в стандартных текстах приводятся лишь асимптотические формулировки, они не сопровождаются оценками точности и, следовательно, мало полезны). Я бы сказал, что обе формулы пригодны лишь при n < 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Я не рассматриваю здесь задачу поиска квантилей: для дискретных распределений она тривиальна, а в тех задачах, где такие распределения возникают, она, как правило, и не актуальна. Если же квантили все-таки понадобятся, рекомендую так переформулировать задачу, чтобы работать с p-значениями (наблюденными значимостями). Вот пример: при реализации некоторых переборных алгоритмов на каждом шаге требуется проверять статистическую гипотезу о биномиальной случайной величине. Согласно классическому подходу на каждом шаге нужно вычислить статистику критерия и сравнить ее значение с границей критического множества. Поскольку, однако, алгоритм переборный, приходится определять границу критического множества каждый раз заново (ведь от шага к шагу объем выборки меняется), что непроизводительно увеличивает временные затраты. Современный подход рекомендует вычислять наблюденную значимость и сравнивать ее с доверительной вероятностью, экономя на поиске квантилей.
Поэтому в приводимых ниже кодах отсутствует вычисление обратной функции, взамен приведена функция rev_binomialDF , которая вычисляет вероятность p успеха в отдельном испытании по заданному количеству n испытаний, числу m успехов в них и значению y вероятности получить эти m успехов. При этом используется вышеупомянутая связь между биномиальным и бета распределениями.
Фактически, эта функция позволяет получать границы доверительных интервалов.
В самом деле, предположим, что в n
биномиальных испытаниях мы получили m
успехов. Как известно, левая граница двухстороннего доверительного интервала
для параметра p с доверительным уровнем
равна 0, если
m = 0, а для
является решением уравнения  .
Аналогично, правая граница равна 1,
если m = n, а для
является решением уравнения
.
Аналогично, правая граница равна 1,
если m = n, а для
является решением уравнения  .
Отсюда вытекает, что для поиска левой границы мы должны решать относительно
уравнение
.
Отсюда вытекает, что для поиска левой границы мы должны решать относительно
уравнение
 ,
а для поиска правой – уравнение
,
а для поиска правой – уравнение
 .
Они и решаются в функциях binom_leftCI и binom_rightCI ,
возвращающих верхнюю и нижнюю границы двустороннего доверительного интервала
соответственно.
.
Они и решаются в функциях binom_leftCI и binom_rightCI ,
возвращающих верхнюю и нижнюю границы двустороннего доверительного интервала
соответственно.
Хочу заметить, что если не нужна совсем уж неимоверная точность, то
при достаточно больших n можно воспользоваться
следующей аппроксимацией [Б.Л. ван дер Варден, Математическая статистика.
М: ИЛ, 1960, гл. 2, разд. 7]:
 ,
где g – квантиль нормального распределения.
Ценность этой аппроксимации в том, что имеются очень простые приближения,
позволяющие вычислять квантили нормального распределения (см. текст о вычислении
нормального распределения и соответствующий раздел данного справочника).
В моей практике (в основном, при n > 100) эта аппроксимация давала примерно 3-4 знака, чего, как правило,
вполне достаточно.
,
где g – квантиль нормального распределения.
Ценность этой аппроксимации в том, что имеются очень простые приближения,
позволяющие вычислять квантили нормального распределения (см. текст о вычислении
нормального распределения и соответствующий раздел данного справочника).
В моей практике (в основном, при n > 100) эта аппроксимация давала примерно 3-4 знака, чего, как правило,
вполне достаточно.
Для вычислений с помощью нижеследующих кодов потребуются файлы betaDF.h , betaDF.cpp (см. раздел о бета-распределении), а также logGamma.h , logGamma.cpp (см. приложение А). Вы можете посмотреть также пример использования функций.
Файл binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double successes, double p); /* * Пусть имеется "trials" независимых наблюдений * с вероятностью "p" успеха в каждом. * Вычисляется вероятность B(successes|trials,p) того, что число * успехов заключено между 0 и "successes" (включительно). */ double rev_binomialDF(double trials, double successes, double y); /* * Пусть известна вероятность y наступления не менее m успехов * в trials испытаниях схемы Бернулли. Функция находит вероятность p * успеха в отдельном испытании. * * В вычислениях используется следующее соотношение * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI(double trials, double successes, double level); /* Пусть имеется "trials" независимых наблюдений * с вероятностью "p" успеха в каждом * и количество успехов равно "successes". * Вычисляется левая граница двустороннего доверительного интервала * с уровнем значимости level. */ double binom_rightCI(double n, double successes, double level); /* Пусть имеется "trials" независимых наблюдений * с вероятностью "p" успеха в каждом * и количество успехов равно "successes". * Вычисляется правая граница двустороннего доверительного интервала * с уровнем значимости level. */ #endif /* Ends #ifndef __BINOMIAL_H__ */ |
Файл binomialDF.cpp
|
/***********************************************************/
/* Биномиальное распределение */
/***********************************************************/
#include |