Метод главных компонент или компонентный анализ (principal component analysis, PCA) - один из важнейших методов в арсенале зоолога или эколога. К сожалению, в тех случаях, когда вполне уместным является применение компонентного анализа, сплошь и рядом применяют кластерный анализ.
Типичная задача, для которой полезен компонентный анализ, такова: есть некое множество объектов, каждый из которых охарактеризован по определенному (достаточно большому) количеству признаков. Исследователя интересуют закономерности, отраженные в разнообразии этих объектов. В том случае, когда есть основания предполагать, что объекты распределены по иерархически соподчиненным группам, можно использовать кластерный анализ - метод классификации (распределения по группам). Если нет оснований ожидать, что в разнообразии объектов отражена какая-то иерархия, логично использовать ординацию (упорядоченное расположение). Если каждый объект охарактеризован по достаточно большому количеству признаков (по крайней мере - такому количеству признаков, какое не получается адекватно отразить на одном графике), оптимально начинать исследование данных с анализа главных компонент. Дело в том, что этот метод является одновременно методом понижения размерности (количества измерений) данных.
Если группа рассматриваемых объектов охарактеризована значениями одного признака, для характеристики их разнообразия можно использовать гистограмму (для непрерывных признаков) или столбчатую диаграмму (для характеристики частот дискретного признака). Если объекты охарактеризованы двумя признаками, можно использовать двумерный график рассеяния, если тремя - трехмерный. А если признаков много? Можно попытаться на двумерном графике отразить взаимное расположение объектов друг относительно друга в многомерном пространстве. Обычно такое понижение размерности связано с потерей информации. Из разных возможных способов такого отображения надо выбрать тот, при котором потеря информации будет минимальной.
Поясним сказанное на самом простом примере: переходе от двумерного пространства к одномерному. Минимальное количество точек, которое задает двумерное пространство (плоскость) - 3. На рис. 9.1.1 показано расположение трех точек на плоскости. Координаты этих точек легко читаются по самому рисунку. Как выбрать прямую, которая будет нести максимальную информацию о взаиморасположении точек?
Рис. 9.1.1. Три точки на плоскости, заданной двумя признаками. На какую прямую будет проецироваться максимальная дисперсия этих точек?
Рассмотрим проекции точек на прямую A (показанную синим цветом). Координаты проекций этих точек на прямую A таковы: 2, 8, 10. Среднее значение - 6 2 / 3 . Дисперсия (2-6 2 / 3)+ (8-6 2 / 3)+ (10-6 2 / 3)=34 2 / 3 .
Теперь рассмотрим прямую B (показанную зеленым цветом). Координаты точек - 2, 3, 7; среднее значение - 4, дисперсия - 14. Таким образом, на прямую B отражается меньшая доля дисперсии, чем на прямую A.
Какова эта доля? Поскольку прямые A и B ортогональны (перпендикулярны), доли общей дисперсии, проецирующиеся на A и B, не пересекаются. Значит, общую дисперсию расположения интересующих нас точек можно вычислить как сумму этих двух слагаемых: 34 2 / 3 +14=48 2 / 3 . При этом на прямую A проецируется 71,2% общей дисперсии, а на прямую B - 28,8%.
А как определить, на какую прямую отразится максимальная доля дисперсии? Эта прямая будет соответствовать линии регрессии для интересующих нас точек, которая обозначена как C (красный цвет). На эту прямую отразится 77,2% общей дисперсии, и это - максимально возможное значение при данном расположении точек. Такую прямую, на которую проецируется максимальная доля общей дисперсии, называют первой главной компонентой .
А на какую прямую отразить оставшиеся 22,8% общей дисперсии? На прямую, перпендикулярную первой главной компоненте. Эта прямая тоже будет являться главной компонентой, ведь на нее отразится максимально возможная доля дисперсии (естественно, без учета той, которая отразилась на первую главную компоненту). Таким образом, это - вторая главная компонента .
Вычислив эти главные компоненты с помощью Statistica (диалог мы опишем чуть позже), мы получим картину, показанную на рис. 9.1.2. Координаты точек на главных компонентах показываются в стандартных отклонениях.

Рис. 9.1.2. Расположение трех точек, показанных на рис. 9.1.1, на плоскости двух главных компонент. Почему эти точки располагаются друг относительно друга иначе, чем на рис. 9.1.1?
На рис. 9.1.2 взаиморасположение точек оказывается измененным. Чтобы в дальнейшем правильно интерпретировать подобные картинки, следует рассмотреть причины отличий в расположении точек на рис. 9.1.1 и 9.1.2 подробнее. Точка 1 в обоих случаях находится правее (имеет большую координату по первому признаку и первой главной компоненте), чем точка 2. Но, почему-то, точка 3 на исходном расположении находится ниже двух других точек (имеет наименьшее значение признака 2), и выше двух других точек на плоскости главных компонент (имеет большую координату по второй компоненте). Это связано с тем, что метод главных компонент оптимизирует именно дисперсию исходных данных, проецирующихся на выбираемые им оси. Если главная компонента коррелирована с какой-то исходной осью, компонента и ось могут быть направлены в одну сторону (иметь положительную корреляцию) или в противоположные стороны (иметь отрицательные корреляции). Оба эти варианта равнозначны. Алгоритм метода главных компонент может «перевернуть» или не «перевернуть» любую плоскость; никаких выводов на основании этого делать не следует.
Однако точки на рис. 9.1.2 не просто «перевернуты» по сравнению с их взаиморасположением на рис. 9.1.1; определенным образом изменилось и их взаиморасположения. Отличия между точками по второй главной компоненте кажутся усиленными. 22,76% общей дисперсии, приходящиеся на вторую компоненту, «раздвинули» точки на такую же дистанцию, как и 77,24% дисперсии, приходящихся на первую главную компоненту.
Чтобы расположение точек на плоскости главных компонент соответствовало их действительному расположению, эту плоскость следовало бы исказить. На рис. 9.1.3. показаны два концентрических круга; их радиусы соотносятся как доли дисперсий, отражаемых первой и второй главными компонентами. Картинка, соответствующая рис. 9.1.2, искажена так, чтобы среднеквадратичное отклонение по первой главной компоненте соответствовало большему кругу, а по второй - меньшему.

Рис. 9.1.3. Мы учли, что на первую главную компоненту приходится бо льшая доля дисперсии, чем на вторую. Для этого мы исказили рис. 9.1.2, подогнав его под два концентрических круга, радиусы которых соотносятся, как доли дисперсий, приходящихся на главные компоненты. Но расположение точек все равно не соответствует исходному, показанному на рис. 9.1.1!
А почему взаимное расположение точек на рис. 9.1.3 не соответствует таковому на рис. 9.1.1? На исходном рисунке, рис. 9.1 точки расположены в соответствии со своими координатами, а не в соответствии с долями дисперсии, приходящимися на каждую ось. Расстоянию в 1 единицу по первому признаку (по оси абсцисс) на рис. 9.1.1 приходятся меньшая доля дисперсии точек по этой оси, чем расстоянию в 1 единицу по второму признаку (по оси ординат). А на рис 9.1.1 расстояния между точками определяются именно теми единицами, в которых измеряются признаки, по которым они описаны.
Несколько усложним задачу. В табл. 9.1.1 показаны координаты 10 точек в 10-мерном пространстве. Первые три точки и первые два измерения - это тот пример, который мы только что рассматривали.
Таблица 9.1.1. Координаты точек для дальнейшего анализа
|
Координаты |
||||||||||
В учебных целях вначале рассмотрим только часть данных из табл. 9.1.1. На рис. 9.1.4 мы видим положение десяти точек на плоскости первых двух признаков. Обратите внимание, что первая главная компонента (прямая C) прошла несколько иначе, чем в предыдущем случае. Ничего удивительного: на ее положение влияют все рассматриваемые точки.

Рис. 9.1.4. Мы увеличили количество точек. Первая главная компонента проходит уже несколько иначе, ведь на нее оказали влияние добавленные точки
На рис. 9.1.5 показано положение рассмотренных нами 10 точек на плоскости двух первых компонент. Обратите внимание: все изменилось, не только доля дисперсии, приходящейся на каждую главную компоненту, но даже положение первых трех точек!

Рис. 9.1.5. Ординация в плоскости первых главных компонент 10 точек, охарактеризованных в табл. 9.1.1. Рассматривались только значения двух первых признаков, последние 8 столбцов табл. 9.1.1 не использовались
В общем, это естественно: раз главные компоненты расположены иначе, то изменилось и взаиморасположение точек.
Трудности в сопоставлении расположения точек на плоскости главных компонент и на исходной плоскости значений их признаков могут вызвать недоумение: зачем использовать такой трудноинтерпретируемый метод? Ответ прост. В том случае, если сравниваемые объекты описаны всего по двум признакам, вполне можно использовать их ординацию по этим, исходным признакам. Все преимущества метода главных компонент проявляются в случае многомерных данных. Метод главных компонент в таком случае оказывается эффективным способом снижения размерности данных.
9.2. Переход к начальным данным с большим количеством измерений
Рассмотрим более сложный случай: проанализируем данные, представленные в табл. 9.1.1 по всем десяти признакам. На рис. 9.2.1 показано, как вызывается окно интересующего нас метода.

Рис. 9.2.1. Запуск метода главных компонент
Нас будет интересовать только выбор признаков для анализа, хотя диалог Statistica позмоляет намного более тонкую настройку (рис. 9.2.2).

Рис. 9.2.2. Выбор переменных для анализа
После выполнения анализа появляется окно его результатов с несколькими вкладками (рис. 9.2.3). Все основные окна доступны уже из первой вкладки.

Рис. 9.2.3. Первая вкладка диалога результатов анализа главных компонент
Можно увидеть, что анализ выделил 9 главных компонент, причем описал с их помощью 100% дисперсии, отраженной в 10 начальных признаках. Это означает, что один признак был лишним, избыточным.
Начнем просматривать результаты с кнопки «Plot case factor voordinates, 2D»: она покажет расположение точек на плоскости, заданной двумя главными компонентами. Нажав эту кнопку, мы попадем в диалог, где надо будет указать, какие мы будем использовать компоненты; естественно начинать анализ с первой и второй компонент. Результат - на рис. 9.2.4.

Рис. 9.2.4. Ординация рассматриваемых объектов на плоскости двух первых главных компонент
Положение точек изменилось, и это естественно: в анализ вовлечены новые признаки. На рис. 9.2.4 отражено более 65% всего разнообразия в положении точек друг относительно друга, и это уже нетривиальный результат. К примеру, вернувшись к табл. 9.1.1, можно убедиться в том, что точки 4 и 7, а также 8 и 10 действительно достаточно близки друг к другу. Впрочем, отличия между ними могут касаться других главных компонент, не показанных на рисунке: на них, все-таки, тоже приходится треть оставшейся изменчивости.
Кстати, при анализе размещения точек на плоскости главных компонент может возникнуть необходимость проанализировать расстояния между ними. Проще всего получить матрицу дистанций между точками с использованием модуля для кластерного анализа.
А как выделенные главные компоненты связаны с исходными признаками? Это можно узнать, нажав кнопку (рис. 9.2.3) Plot var. factor coordinates, 2D. Результат - на рис. 9.2.5.

Рис. 9.2.5. Проекции исходных признаков на плоскость двух первых главных компонент
Мы смотрим на плоскость двух главных компонент «сверху». Исходные признаки, которые никак не связаны с главными компонентами, будет перпендикулярны (или почти перпендикулярны) им и отразятся короткими отрезками, заканчивающимися вблизи начала координат. Так, меньше всего с двумя первыми главными компонентами связан признак № 6 (хотя он демонстрирует определенную положительную корреляцию с первой компонентой). Отрезки, соответствующие тем признакам, которые полностью отразятся на плоскости главных компонент, будут заканчиваться на охватывающей центр рисунка окружности единичного радиуса.
Например, можно увидеть, что на первую главную компоненту сильнее всего повлияли признаки 10 (связан положительной корреляцией), а также 7 и 8 (связаны отрицательной корреляцией). Чтобы рассмотреть структуру таких корреляций подробнее, можно нажать кнопку Factor coordinates of variables, и получить таблицу, показанную на рис. 9.2.6.

Рис. 9.2.6. Корреляции между исходными признаками и выделенными главными компонентами (Factors)
Кнопка Eigenvalues выводит величины, которые называются собственными значениями главных компонент . В верхней части окна, показанного на рис. 9.2.3, выведены такие значения для нескольких первых компонент; кнопка Scree plot показывает их в удобной для восприятия форме (рис. 9.2.7).

Рис. 9.2.7. Собственные значения выделенных главных компонент и доли отраженной ими общей дисперсии
Для начала надо понять, что именно показывает значение eigenvalue. Это - мера дисперсии, отразившейся на главную компоненту, измеренная в количестве дисперсии, приходившейся на каждый признак в начальных данных. Если eigenvalue первой главной компоненты равен 3,4, это означает, что на нее отражается больше дисперсии, чем на три признака из начального набора. Собственные величины линейно связаны с долей дисперсии, приходящейся на главную компоненту, единое что, сумма собственных значений равна количеству исходных признаков, а сумма долей дисперсии равна 100%.
А что означает, что информацию об изменчивости по 10 признакам удалось отразить в 9 главных компонентах? Что один из начальных признаков был избыточным, не добавлял никакой новой информации. Так и было; на рис. 9.2.8 показано, как был сгенерирован набор точек, отраженный в табл. 9.1.1.
Исходной для анализа является матрица данных
размерности
 ,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям
,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям .
Исходные данные нормируются, для чего
вычисляются средние значения показателей
.
Исходные данные нормируются, для чего
вычисляются средние значения показателей ,
а также значения стандартных отклонений
,
а также значения стандартных отклонений .
Тогда матрица нормированных значений
.
Тогда матрица нормированных значений

с
элементами

Рассчитывается матрица парных коэффициентов корреляции:

На
главной диагонали матрицы расположены
единичные элементы
 .
.
Модель компонентного анализа строится путем представления исходных нормированных данных в виде линейной комбинации главных компонент:

где
 -
«вес», т.е. факторная нагрузка
-
«вес», т.е. факторная нагрузка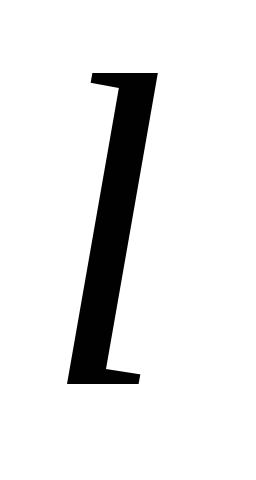 -й
главной компоненты на
-й
главной компоненты на -ю
переменную;
-ю
переменную;
 -значение
-значение
 -й
главной компоненты для
-й
главной компоненты для -го
наблюдения (объекта), где
-го
наблюдения (объекта), где .
.
В матричной форме модель имеет вид

здесь
 - матрица главных компонент размерности
- матрица главных компонент размерности ,
,
 -
матрица факторных нагрузок той же
размерности.
-
матрица факторных нагрузок той же
размерности.
Матрица
 описывает
описывает наблюдений в пространстве
наблюдений в пространстве главных компонент. При этом элементы
матрицы
главных компонент. При этом элементы
матрицы нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что
нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что ,
где
,
где – единичная матрица размерности
– единичная матрица размерности .
.
Элемент
 матрицы
матрицы характеризует тесноту линейной связи
между исходной переменной
характеризует тесноту линейной связи
между исходной переменной и главной компонентой
и главной компонентой ,
следовательно, принимает значения
,
следовательно, принимает значения .
.
Корреляционная
матрица
 может быть выражена через матрицу
факторных нагрузок
может быть выражена через матрицу
факторных нагрузок .
.
По
главной диагонали корреляционной
матрицы располагаются единицы и по
аналогии с ковариационной матрицей они
представляют собой дисперсии используемых
 -признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы
-признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы -признаков
в выборочной совокупности объема
-признаков
в выборочной совокупности объема равна сумме этих единиц, т.е. равна следу
корреляционной матрицы
равна сумме этих единиц, т.е. равна следу
корреляционной матрицы .
.
Корреляционная матриц может быть преобразована в диагональную, то есть матрицу, все значения которой, кроме диагональных, равны нулю:
 ,
,
где
 - диагональная матрица, на главной
диагонали которой находятся собственные
числа
- диагональная матрица, на главной
диагонали которой находятся собственные
числа корреляционной матрицы,
корреляционной матрицы, - матрица, столбцы которой – собственные
вектора корреляционной матрицы
- матрица, столбцы которой – собственные
вектора корреляционной матрицы .
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения
.
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения для любых
для любых .
.
Собственные
значения
 находятся как корни характеристического
уравнения
находятся как корни характеристического
уравнения

Собственный
вектор
 ,
соответствующий собственному значению
,
соответствующий собственному значению корреляционной матрицы
корреляционной матрицы ,
определяется как отличное от нуля
решение уравнения
,
определяется как отличное от нуля
решение уравнения

Нормированный
собственный вектор
 равен
равен

Превращение
в нуль недиагональных членов означает,
что признаки становятся независимыми
друг от друга ( при
при ).
).
Суммарная
дисперсия всей системы
 переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений
переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений корреляционной матрицы для каждого из
корреляционной матрицы для каждого из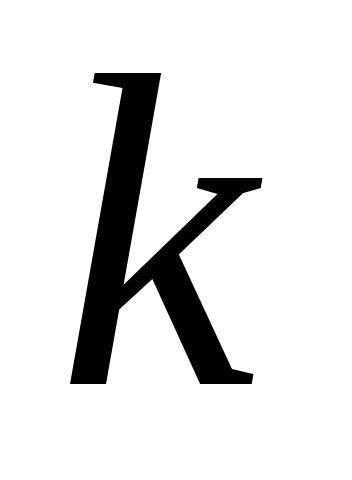 -признаков.
Сумма этих собственных значений
-признаков.
Сумма этих собственных значений равна следу корреляционной матрицы,
т.е.
равна следу корреляционной матрицы,
т.е. ,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков
,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков в условиях, если бы признаки были бы
независимыми друг от друга.
в условиях, если бы признаки были бы
независимыми друг от друга.
В
методе главных компонент сначала по
исходным данным рассчитывается
корреляционная матрица. Затем производят
её ортогональное преобразование и
посредством этого находят факторные
нагрузки
 для всех
для всех переменных и
переменных и факторов (матрицу факторных нагрузок),
собственные значения
факторов (матрицу факторных нагрузок),
собственные значения и определяют веса факторов.
и определяют веса факторов.
Матрицу
факторных нагрузок А можно определить
как
 ,
а
,
а -й
столбец матрицы А - как
-й
столбец матрицы А - как .
.
Вес
факторов
 или
или отражает долю в общей дисперсии, вносимую
данным фактором.
отражает долю в общей дисперсии, вносимую
данным фактором.
Факторные
нагрузки изменяются от –1 до +1 и являются
аналогом коэффициентов корреляции. В
матрице факторных нагрузок необходимо
выделить значимые и незначимые нагрузки
с помощью критерия Стьюдента
 .
.
Сумма
квадратов нагрузок
 -го
фактора во всех
-го
фактора во всех -признаках
равна собственному значению данного
фактора
-признаках
равна собственному значению данного
фактора .
Тогда
.
Тогда -вклад
i-ой переменной в % в формировании j-го
фактора.
-вклад
i-ой переменной в % в формировании j-го
фактора.
Сумма
квадратов всех факторных нагрузок по
строке равна единице, полной дисперсии
одной переменной, а всех факторов по
всем переменным равна суммарной дисперсии
(т.е. следу или порядку корреляционной
матрицы, или сумме её собственных
значений)
 .
.
В
общем виде факторная структура i–го
признака представляется в форме
 ,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
 ,
,
где
 – значение j-ого фактора у t-ого
наблюдения,
– значение j-ого фактора у t-ого
наблюдения, -стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки;
-стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки; –факторная нагрузка,
–факторная нагрузка, –собственное значение, отвечающее
фактору j. Эти вычисленные значения
–собственное значение, отвечающее
фактору j. Эти вычисленные значения широко используются для графического
представления результатов факторного
анализа.
широко используются для графического
представления результатов факторного
анализа.
По
матрице факторных нагрузок может быть
восстановлена корреляционная матрица:
 .
.
Часть дисперсии переменной, объясняемая главными компонентами, называется общностью
 ,
,
где
 - номер переменной, а
- номер переменной, а -номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
-номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
Удельный
вклад
 -й
главной компоненты определяется по
формуле
-й
главной компоненты определяется по
формуле
 .
.
Суммарный
вклад учитываемых
 главных компонент определяется из
выражения
главных компонент определяется из
выражения
 .
.
Обычно
для анализа используют
 первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
Матрица факторных нагрузок А используется для интерпретации главных компонент, при этом обычно рассматриваются те значения, которые превышают 0,5.
Значения главных компонент задаются матрицей

Метод главных компонент – это метод, который переводит большое количество связанных между собой (зависимых, коррелирующих) переменных в меньшее количество независимых переменных, так как большое количество переменных часто затрудняет анализ и интерпретацию информации. Строго говоря, этот метод не относится к факторному анализу, хотя и имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу исходных переменных; во-вторых, постулируется возможность полного разложения дисперсии всех исходных переменных, т.е. ее полное объяснение через латентные факторы (обобщенные признаки).
Например, представим, что мы провели исследование, в котором измерили у студентов интеллект по тесту Векслера, тесту Айзенка, тесту Равена, а также успеваемость по социальной, когнитивной и общей психологии. Вполне возможно, что показатели различных тестов на интеллект будут коррелировать между собой, так как они, в конце концов, измеряют одну характеристику испытуемого – его интеллектуальные способности, хотя и по-разному. Если переменных в исследовании слишком много (x 1 , x 2 , …, x p ) , а некоторые из них взаимосвязаны, то у исследователя иногда возникает желание уменьшить сложность данных, сократив количество переменных. Для этого и служит метод главных компонент, который создает несколько новых переменных y 1 , y 2 , …, y p , каждая из которых является линейной комбинацией первоначальных переменных x 1 , x 2 , …, x p :
y 1 =a 11 x 1 +a 12 x 2 +…+a 1p x p
y 2 =a 21 x 1 +a 22 x 2 +…+a 2p x p
… (1)
y p =a p1 x 1 +a p2 x 2 +…+a pp x p
Переменные y 1 , y 2 , …, y p называются главными компонентами или факторами. Таким образом, фактор – это искусственный статистический показатель, возникающий в результате специальных преобразований корреляционной матрицы . Процедура извлечения факторов называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, определяемые в результате факторизации, как правило, не равноценны по своему значению.
Коэффициенты a ij , определяющие новую переменную, выбираются таким образом, чтобы новые переменные (главные компоненты, факторы) описывали максимальное количество вариативности данных и не коррелировали между собой. Часто полезно представить коэффициенты a ij таким образом, чтобы они представляли собой коэффициент корреляции между исходной переменной и новой переменной (фактором). Это достигается умножением a ij на стандартное отклонение фактора. В большинстве статистических пакетов так и делается (в программе STATISTICA тоже). Коэффициенты a ij Обычно они представляются в виде таблицы, где факторы располагаются в виде столбцов, а переменные в виде строк:
Такая таблица называется таблицей (матрицей) факторных нагрузок. Числа, приведенные в ней, являются коэффициентами a ij .Число 0,86 означает, что корреляция между первым фактором и значением по тесту Векслера равна 0,86. Чем выше факторная нагрузка по абсолютной величине, тем сильнее связь переменной с фактором.
Компонентный анализ относится к многомерным методам снижения размерности. Он содержит один метод - метод главных компонент. Главные компоненты представляют собой ортогональную систему координат, в которой дисперсии компонент характеризуют их статистические свойства.
Учитывая, что объекты исследования в экономике характеризуются большим, но конечным количеством признаков, влияние которых подвергается воздействию большого количества случайных причин.
Вычисление главных компонент
Первой главной компонентой Z1 исследуемой системы признаков Х1, Х2, Х3 , Х4 ,…, Хn называется такая центрировано - нормированная линейная комбинация этих признаков, которая среди прочих центрировано - нормированных линейных комбинаций этих признаков, имеет дисперсию наиболее изменчивую.
В качестве второй главной компоненты Z2 мы будем брать такую центрировано - нормированную комбинацию этих признаков, которая:
не коррелированна с первой главной компонентой,
не коррелированны с первой главной компонентой, эта комбинация имеет наибольшую дисперсию.
K-ой главной компонентой Zk (k=1…m) мы будем называть такую центрировано - нормированную комбинацию признаков, которая:
не коррелированна с к-1 предыдущими главными компонентами,
среди всех возможных комбинаций исходных признаков, которые не
не коррелированны с к-1 предыдущими главными компонентами, эта комбинация имеет наибольшую дисперсию.
Введём ортогональную матрицу U и перейдём от переменных Х к переменным Z, причём
Вектор выбирается т. о., чтобы дисперсия была максимальной. После получения выбирается т. о., чтобы дисперсия была максимальной при условии, что не коррелированно с и т. д.
Так как признаки измерены в несопоставимых величинах, то удобнее будет перейти к центрированно-нормированным величинам. Матрицу исходных центрированно-нормированных значений признаков найдем из соотношения:

где - несмещенная, состоятельная и эффективная оценка математического ожидания,
Несмещенная, состоятельная и эффективная оценка дисперсии.
Матрица наблюденных значений исходных признаков приведена в Приложении.
Центрирование и нормирование произведено с помощью программы"Stadia".
Так как признаки центрированы и нормированы, то оценку корреляционной матрицы можно произвести по формуле:

Перед тем как проводить компонентный анализ, проведем анализ независимости исходных признаков.
Проверка значимости матрицы парных корреляций с помощью критерия Уилкса.
Выдвигаем гипотезу:
Н0: незначима
Н1: значима
125,7; (0,05;3,3) = 7,8
т.к > , то гипотеза Н0 отвергается и матрица является значимой, следовательно, имеет смысл проводить компонентный анализ.
Проверим гипотезу о диагональности ковариационной матрицы
Выдвигаем гипотезу:
Строим статистику, распределена по закону с степенями свободы.
123,21, (0,05;10) =18,307
т.к >, то гипотеза Н0 отвергается и имеет смысл проводить компонентный анализ.
Для построения матрицы факторных нагрузок необходимо найти собственные числа матрицы, решив уравнение.
Используем для этой операции функцию eigenvals системы MathCAD, которая возвращает собственные числа матрицы:
Т.к. исходные данные представляют собой выборку из генеральной совокупности, то мы получили не собственные числа и собственные вектора матрицы, а их оценки. Нас будет интересовать на сколько “хорошо” со статистической точки зрения выборочные характеристики описывают соответствующие параметры для генеральной совокупности.
Доверительный интервал для i-го собственного числа ищется по формуле:

Доверительные интервалы для собственных чисел в итоге принимают вид:

Оценка значения нескольких собственных чисел попадает в доверительный интервал других собственных чисел. Необходимо проверить гипотезу о кратности собственных чисел.
Проверка кратности производится с помощью статистики
где r-количество кратных корней.
Данная статистика в случае справедливости распределена по закону с числом степеней свободы. Выдвинем гипотезы:
Так как, то гипотеза отвергается, то есть собственные числа и не кратны.
Так как, то гипотеза отвергается, то есть собственные числа и не кратны.
Необходимо выделить главные компоненты на уровне информативности 0,85. Мера информативности показывает какую часть или какую долю дисперсии исходных признаков составляют k-первых главных компонент. Мерой информативности будем называть величину:
На заданном уровне информативности выделено три главных компоненты.
Запишем матрицу =

Для получения нормализованного вектора перехода от исходных признаков к главным компонентам необходимо решить систему уравнений: , где - соответствующее собственное число. После получения решения системы необходимо затем нормировать полученный вектор.
Для решения данной задачи воспользуемся функцией eigenvec системы MathCAD, которая возвращает нормированный вектор для соответствующего собственного числа.
В нашем случае первых четырех главных компонент достаточно для достижения заданного уровня информативности, поэтому матрица U (матрица перехода от исходного базиса к базису из собственных векторов)
Строим матрицу U, столбцами которой являются собственные вектора:

Матрица весовых коэффициентов:


Коэффициенты матрицы А являются коэффициентами корреляции между центрировано - нормированными исходными признаками и ненормированными главными компонентами, и показывают наличие, силу и направление линейной связи между соответствующими исходными признаками и соответствующими главными компонентами.
В этой статье я бы хотел рассказать о том, как именно работает метод анализа главных компонент (PCA – principal component analysis) с точки зрения интуиции, стоящей за ее математическим аппаратом. Максимально просто, но подробно.
Математика вообще очень красивая и изящная наука, но порой ее красота скрывается за кучей слоев абстракции. Показать эту красоту лучше всего на простых примерах, которые, так сказать, можно покрутить, поиграть и пощупать, потому что в конце концов все оказывается гораздо проще, чем кажется на первый взгляд – самое главное понять и представить.
В анализе данных, как и в любом другом анализе, порой бывает нелишним создать упрощенную модель, максимально точно описывающую реальное положение дел. Часто бывает так, что признаки довольно сильно зависят друг от друга и их одновременное наличие избыточно.
К примеру, расход топлива у нас меряется в литрах на 100 км, а в США в милях на галлон. На первый взгляд, величиные разные, но на самом деле они строго зависят друг от друга. В миле 1600км, а в галлоне 3.8л. Один признак строго зависит от другого, зная один, знаем и другой.
Но гораздо чаще бывает так, что признаки зависят друг от друга не так строго и (что важно!) не так явно. Объем двигателя в целом положительно влияет на разгон до 100 км/ч, но это верно не всегда. А еще может оказаться, что с учетом не видимых на первый взгляд факторов (типа улучшения качества топлива, использования более легких материалов и прочих современных достижений), год автомобиля не сильно, но тоже влияет на его разгон.
Зная зависимости и их силу, мы можем выразить несколько признаков через один, слить воедино, так сказать, и работать уже с более простой моделью. Конечно, избежать потерь информации, скорее всего не удастся, но минимизировать ее нам поможет как раз метод PCA.
Выражаясь более строго, данный метод аппроксимирует n-размерное облако наблюдений до эллипсоида (тоже n-мерного), полуоси которого и будут являться будущими главными компонентами. И при проекции на такие оси (снижении размерности) сохраняется наибольшее количество информации.
Шаг 1. Подготовка данных
Здесь для простоты примера я не буду брать реальные обучающие датасеты на десятки признаков и сотни наблюдений, а сделаю свой, максимально простой игрушечный пример. 2 признака и 10 наблюдений будет вполне достаточно для описания того, что, а главное – зачем, происходит в недрах алгоритма.
Сгенерируем выборку:

X = np.arange(1,11) y = 2 * x + np.random.randn(10)*2 X = np.vstack((x,y)) print X OUT: [[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. ] [ 2.73446908 4.35122722 7.21132988 11.24872601 9.58103444 12.09865079 13.78706794 13.85301221 15.29003911 18.0998018 ]]
В данной выборке у нас имеются два признака, сильно коррелирующие друг с другом. С помощью алгоритма PCA мы сможем легко найти признак-комбинацию и, ценой части информации, выразить оба этих признака одним новым. Итак, давайте разбираться!
Для начала немного статистики. Вспомним, что для описания случайной величины используются моменты. Нужные нам – мат. ожидание и дисперсия. Можно сказать, что мат. ожидание – это «центр тяжести» величины, а дисперсия – это ее «размеры». Грубо говоря, мат. ожидание задает положение случайной величины, а дисперсия – ее размер.
Сам процесс проецирования на вектор никак не влияет на значения средних, так как для минимизации потерь информации наш вектор должен проходить через центр нашей выборки. Поэтому нет ничего страшного, если мы отцентрируем нашу выборку – линейно сдвинем ее так, чтобы средние значения признаков были равны 0. Это очень сильно упростит наши дальнейшие вычисления (хотя, стоит отметить, что можно обойтись и без центрирования).
Оператор, обратный сдвигу будет равен вектору изначальных средних значений – он понадобится для восстановления выборки в исходной размерности.

Xcentered = (X - x.mean(), X - y.mean()) m = (x.mean(), y.mean()) print Xcentered print "Mean vector: ", m OUT: (array([-4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5]), array([-8.44644233, -8.32845585, -4.93314426, -2.56723136, 1.01013247, 0.58413394, 1.86599939, 7.00558491, 4.21440647, 9.59501658])) Mean vector: (5.5, 10.314393916)
Дисперсия же сильно зависит от порядков значений случайной величины, т.е. чувствительна к масштабированию. Поэтому если единицы измерения признаков сильно различаются своими порядками, крайне рекомендуется стандартизировать их. В нашем случае значения не сильно разнятся в порядках, так что для простоты примера мы не будем выполнять эту операцию.
Шаг 2. Ковариационная матрица
В случае с многомерной случайной величиной (случайным вектором) положение центра все так же будет являться мат. ожиданиями ее проекций на оси. А вот для описания ее формы уже недостаточно толькое ее дисперсий по осям. Посмотрите на эти графики, у всех трех случайных величин одинаковые мат.ожидания и дисперсии, а их проекции на оси в целом окажутся одинаковы!

Для описания формы случайного вектора необходима ковариационная матрица.
Это матрица, у которой (i,j) -элемент является корреляцией признаков (X i , X j). Вспомним формулу ковариации:
В нашем случае она упрощается, так как E(X i) = E(X j) = 0:
Заметим, что когда X i = X j:
и это справедливо для любых случайных величин.
Таким образом, в нашей матрице по диагонали будут дисперсии признаков (т.к. i = j), а в остальных ячейках – ковариации соответствующих пар признаков. А в силу симметричности ковариации матрица тоже будет симметрична.
Замечание: Ковариационная матрица является обобщением дисперсии на случай многомерных случайных величин – она так же описывает форму (разброс) случайной величины, как и дисперсия.
И действительно, дисперсия одномерной случайной величины – это ковариационная матрица размера 1x1, в которой ее единственный член задан формулой Cov(X,X) = Var(X).
Итак, сформируем ковариационную матрицу Σ
для нашей выборки. Для этого посчитаем дисперсии X i и X j , а также их ковариацию. Можно воспользоваться вышенаписанной формулой, но раз уж мы вооружились Python’ом, то грех не воспользоваться функцией numpy.cov(X)
. Она принимает на вход список всех признаков случайной величины и возвращает ее ковариационную матрицу и где X – n-мерный случайный вектор (n-количество строк). Функция отлично подходит и для расчета несмещенной дисперсии, и для ковариации двух величин, и для составления ковариационной матрицы.
(Напомню, что в Python матрица представляется массивом-столбцом массивов-строк.)
Covmat = np.cov(Xcentered) print covmat, "n" print "Variance of X: ", np.cov(Xcentered) print "Variance of Y: ", np.cov(Xcentered) print "Covariance X and Y: ", np.cov(Xcentered) OUT: [[ 9.16666667 17.93002811] [ 17.93002811 37.26438587]] Variance of X: 9.16666666667 Variance of Y: 37.2643858743 Covariance X and Y: 17.9300281124
Шаг 3. Собственные вектора и значения (айгенпары)
О"кей, мы получили матрицу, описывающую форму нашей случайной величины, из которой мы можем получить ее размеры по x и y (т.е. X 1 и X 2), а также примерную форму на плоскости. Теперь надо надо найти такой вектор (в нашем случае только один), при котором максимизировался бы размер (дисперсия) проекции нашей выборки на него.
Замечание: Обобщение дисперсии на высшие размерности - ковариационная матрица, и эти два понятия эквивалентны. При проекции на вектор максимизируется дисперсия проекции, при проекции на пространства больших порядков – вся ее ковариационная матрица.
Итак, возьмем единичный вектор на который будем проецировать наш случайный вектор X. Тогда проекция на него будет равна v T X. Дисперсия проекции на вектор будет соответственно равна Var(v T X). В общем виде в векторной форме (для центрированных величин) дисперсия выражается так:
Соответственно, дисперсия проекции:
Легко заметить, что дисперсия максимизируется при максимальном значении v T Σv. Здесь нам поможет отношение Рэлея. Не вдаваясь слишком глубоко в математику, просто скажу, что у отношения Рэлея есть специальный случай для ковариационных матриц:
Последняя формула должна быть знакома по теме разложения матрицы на собственные вектора и значения. x является собственным вектором, а λ – собственным значением. Количество собственных векторов и значений равны размеру матрицы (и значения могут повторяться).
Кстати, в английском языке собственные значения и векторы именуются eigenvalues и eigenvectors соответственно.
Мне кажется, это звучит намного более красиво (и кратко), чем наши термины.
Таким образом, направление максимальной дисперсии у проекции всегда совпадает с айгенвектором имеющим максимальное собственное значение, равное величине этой дисперсии .
И это справедливо также для проекций на большее количество измерений – дисперсия (ковариационная матрица) проекции на m-мерное пространство будет максимальна в направлении m айгенвекторов, имеющих максимальные собственные значения.
Размерность нашей выборки равна двум и количество айгенвекторов у нее, соответственно, 2. Найдем их.
В библиотеке numpy реализована функция numpy.linalg.eig(X) , где X – квадратная матрица. Она возвращает 2 массива – массив айгензначений и массив айгенвекторов (векторы-столбцы). И векторы нормированы - их длина равна 1. Как раз то, что надо. Эти 2 вектора задают новый базис для выборки, такой что его оси совпадают с полуосями аппроксимирующего эллипса нашей выборки.

На этом графике мы апроксимировали нашу выборку эллипсом с радиусами в 2 сигмы (т.е. он должен содержать в себе 95% всех наблюдений – что в принципе мы здесь и наблюдаем). Я инвертировал больший вектор (функция eig(X) направляла его в обратную сторону) – нам важно направление, а не ориентация вектора.
Шаг 4. Снижение размерности (проекция)
Наибольший вектор имеет направление, схожее с линией регрессии и спроецировав на него нашу выборку мы потеряем информацию, сравнимую с суммой остаточных членов регрессии (только расстояние теперь евклидово, а не дельта по Y). В нашем случае зависимость между признаками очень сильная, так что потеря информации будет минимальна. «Цена» проекции - дисперсия по меньшему айгенвектору - как видно из предыдущего графика, очень невелика.
Замечание: диагональные элементы ковариационной матрицы показывают дисперсии по изначальному базису, а ее собственные значения – по новому (по главным компонентам).
Часто требуется оценить объем потерянной (и сохраненной) информации. Удобнее всего представить в процентах. Мы берем дисперсии по каждой из осей и делим на общую сумму дисперсий по осям (т.е. сумму всех собственных чисел ковариационной матрицы).
Таким образом, наш больший вектор описывает 45.994 / 46.431 * 100% = 99.06%, а меньший, соответственно, примерно 0.94%. Отбросив меньший вектор и спроецировав данные на больший, мы потеряем меньше 1% информации! Отличный результат!
Замечание: На практике, в большинстве случаев, если суммарная потеря информации составляет не более 10-20%, то можно спокойно снижать размерность.
Для проведения проекции, как уже упоминалось ранее на шаге 3, надо провести операцию v T X (вектор должен быть длины 1). Или, если у нас не один вектор, а гиперплоскость, то вместо вектора v T берем матрицу базисных векторов V T . Полученный вектор (или матрица) будет являться массивом проекций наших наблюдений.
V = (-vecs, -vecs) Xnew = dot(v,Xcentered) print Xnew OUT: [ -9.56404107 -9.02021624 -5.52974822 -2.96481262 0.68933859 0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
dot(X,Y) - почленное произведение (так мы перемножаем векторы и матрицы в Python)
Нетрудно заметить, что значения проекций соответствуют картине на предыдущем графике.
Шаг 5. Восстановление данных
С проекцией удобно работать, строить на ее основе гипотезы и разрабатывать модели. Но не всегда полученные главные компоненты будут иметь явный, понятный постороннему человеку, смысл. Иногда полезно раскодировать, к примеру, обнаруженные выбросы, чтобы посмотреть, что за наблюдения за ними стоят.
Это очень просто. У нас есть вся необходимая информация, а именно координаты базисных векторов в исходном базисе (векторы, на которые мы проецировали) и вектор средних (для отмены центровки). Возьмем, к примеру, наибольшее значение: 10.596… и раскодируем его. Для этого умножим его справа на транспонированный вектор и прибавим вектор средних, или в общем виде для всей выбоки: X T v T +m
Xrestored = dot(Xnew,v) + m print "Restored: ", Xrestored print "Original: ", X[:,9] OUT: Restored: [ 10.13864361 19.84190935] Original: [ 10. 19.9094105]
Разница небольшая, но она есть. Ведь потерянная информация не восстанавливается. Тем не менее, если простота важнее точности, восстановленное значение отлично аппроксимирует исходное.
Вместо заключения – проверка алгоритма
Итак, мы разобрали алгоритм, показали как он работает на игрушечном примере, теперь осталось только сравнить его с PCA, реализованным в sklearn – ведь пользоваться будем именно им.
From sklearn.decomposition import PCA pca = PCA(n_components = 1) XPCAreduced = pca.fit_transform(transpose(X))
Параметр n_components указывает на количество измерений, на которые будет производиться проекция, то есть до скольки измерений мы хотим снизить наш датасет. Другими словами – это n айгенвекторов с самыми большими собственными числами. Проверим результат снижения размерности:
Print "Our reduced X: n", Xnew print "Sklearn reduced X: n", XPCAreduced OUT: Our reduced X: [ -9.56404106 -9.02021625 -5.52974822 -2.96481262 0.68933859 0.74406645 2.33433492 7.39307974 5.3212742 10.59672425] Sklearn reduced X: [[ -9.56404106] [ -9.02021625] [ -5.52974822] [ -2.96481262] [ 0.68933859] [ 0.74406645] [ 2.33433492] [ 7.39307974] [ 5.3212742 ] [ 10.59672425]]
Мы возвращали результат как матрицу вектор-столбцов наблюдений (это более канонический вид с точки зрения линейной алгебры), PCA в sklearn же возвращает вертикальный массив.
В принципе, это не критично, просто стоит отметить, что в линейной алгебре канонично записывать матрицы через вектор-столбцы, а в анализе данных (и прочих связанных с БД областях) наблюдения (транзакции, записи) обычно записываются строками.
Проверим и прочие параметры модели – функция имеет ряд атрибутов, позволяющих получить доступ к промежуточным переменным:
Вектор средних: mean_
- Вектор(матрица) проекции: components_
- Дисперсии осей проекции (выборочная): explained_variance_
- Доля информации (доля от общей дисперсии): explained_variance_ratio_
Замечание: explained_variance_ показывает выборочную дисперсию, тогда как функция cov() для построения ковариационной матрицы рассчитывает несмещенные дисперсии!
Сравним полученные нами значения со значениями библиотечной функции.
Print "Mean vector: ", pca.mean_, m print "Projection: ", pca.components_, v print "Explained variance ratio: ", pca.explained_variance_ratio_, l/sum(l) OUT: Mean vector: [ 5.5 10.31439392] (5.5, 10.314393916) Projection: [[ 0.43774316 0.89910006]] (0.43774316434772387, 0.89910006232167594) Explained variance: [ 41.39455058] 45.9939450918 Explained variance ratio: [ 0.99058588] 0.990585881238
Единственное различие – в дисперсиях, но как уже упоминалось, мы использовали функцию cov(), которая использует несмещенную дисперсию, тогда как атрибут explained_variance_ возвращает выборочную. Они отличаются только тем, что первая для получения мат.ожидания делит на (n-1), а вторая – на n. Легко проверить, что 45.99 ∙ (10 - 1) / 10 = 41.39.
Все остальные значения совпадают, что означает, что наши алгоритмы эквивалентны. И напоследок замечу, что атрибуты библиотечного алгоритма имеют меньшую точность, поскольку он наверняка оптимизирован под быстродействие, либо просто для удобства округляет значения (либо у меня какие-то глюки).
Замечание: библиотечный метод автоматически проецирует на оси, максимизирующие дисперсию. Это не всегда рационально. К примеру, на данном рисунке неаккуратное снижение размерности приведет к тому, что классификация станет невозможна. Тем не менее, проекция на меньший вектор успешно снизит размерность и сохранит классификатор.

Итак, мы рассмотрели принципы работы алгоритма PCA и его реализации в sklearn. Я надеюсь, эта статья была достаточно понятна тем, кто только начинает знакомство с анализом данных, а также хоть немного информативна для тех, кто хорошо знает данный алгоритм. Интуитивное представление крайне полезно для понимания того как работает метод, а понимание очень важно для правильной настройки выбранной модели. Спасибо за внимание!
P.S.: Просьба не ругать автора за возможные неточности. Автор сам в процессе знакомства с дата-анализом и хочет помочь таким же как он в процессе освоения этой удивительной области знаний! Но конструктивная критика и разнообразный опыт всячески приветствуются!